CRDTs: Eliminating the Central Server in Collaborative Editing

If 2020 has shown us nothing else, it’s made clear that remote collaboration is no longer a nice to have, but a necessity. Customers and employees are working in isolation, across cities, states, and even countries. Being at home introduces further complications where computer networks are less stable and cellular data may be the only option. Applications which are not only resilient to network outages but also support — no, encourage — remote collaboration is the new expectation.
With that in mind, it’s important to state the obvious: concurrency is hard. There are a great many technologies and techniques available to software developers to mitigate the inevitable conflicts that will occur throughout every level of the software stack. These include using immutable objects, tracking incremented object versions, wrapping mutations in database transactions, locking database records and tables, and throwing application mutexes in and around critical code paths among many others.
All of these techniques (and many more) exist to try to limit or avoid concurrency problems, such as:
- What happens when two users simultaneously change the same text?
- How do we notify the losing editor and give them the right (canonical) data?
- With intermittent network connectivity, how do we avoid processing multiple, duplicate modification requests?
Concurrency, Collaboration, and Agreement
Concurrency problems are exponentially more difficult to solve for flash sale sites (think Gilt, HauteLook, and Groupon) which specialize in selling limited inventory in short, highly-marketed blast sales. These sites specialize in dealing with extremely high concurrency and the problems around it. Who gets their items when globally-dispersed data centers of servers are all processing an avalanche of simultaneous requests? These sites can’t promise, charge for, and ship products which they don’t have and can’t acquire more of in the future.
And these examples only focus on consumer-facing concurrency and consistency. There are many other affected areas on the infrastructure-side as well, including distributed caching, data replication, and multi-master writing.
We exhaust ourselves spending enormous amounts of time and energy to control the impacts of concurrency. Trying to avoid these problems is ultimately a fool’s errand. What if instead we recognize and embrace concurrency and convert it into our competitive advantage?
One avenue toward that end has about a decade of research and development behind it and is becoming increasingly popular. It’s a category of data types and algorithms collectively referred to as Conflict-Free Replicated Data Types (or CRDTs). For many applications, using CRDTs to embrace collaboration may allow you to harness collaboration in a more straightforward way than you might think. That said, to understand CRDTs, it’s useful to have an idea of what came before them.
Taming Concurrency with Operational Transforms
Google Docs is a fantastic example of an application which embraces concurrent collaboration. It launched about a decade ago and quickly became — and still remains — the standard for collaborative document editing. It allows up to 100 different people to edit a single document all at the same time.
Like its research-based predecessor, Google Wave, Google Docs was built around an earlier, but still very widely utilized concept from 1989 called Operational Transformation (or OTs). The idea is relatively simple: Every change is a small operation applied to a specific location. Combining all of these change operations is then the job of a referee or gatekeeper, likely a single server. This resolution process creates a single source of truth, or canonical set of operations and results, which are distributed back out to all users.
Problems with Centralized Servers
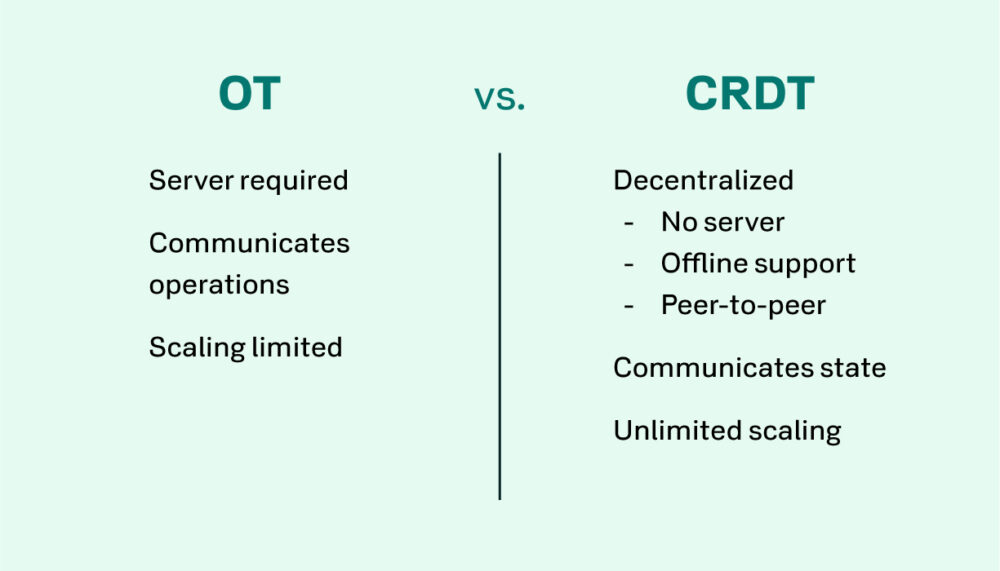
If obviously-successful products like Google Docs use OTs, why ignore that to look toward CRDTs? There are a few different problems with OTs which CRDTs were built to solve. The single, most egregious problem is that OTs require a single, central server (or gatekeeper) to receive, execute, store, and track the canonical operations and final canonical state.
Without this gatekeeper, the OT system is back into a problematic multi-master configuration. In this configuration, conflicts can occur when the masters receive different updates and splinter apart in disagreement. By extension, this then means that OTs do not work when the central system is unavailable or unreachable. This, in turn means that OTs fail in an intermittent network environment. And, the longer that this system is unreachable, the more diverged each user’s local copies of a document become. The more diverged they get, the more mangled and conflicting the final document will become when communications are restored and these operations are later resolved.
Furthermore, the need of a single gatekeeper with whom all parties must talk goes directly against the benefits of using an elastic and efficient cloud-based infrastructure. In a dynamic server environment where systems can come and go, there must be special accommodations for OT-based systems to create and enforce “user-to-server affinity.” This affinity ties all collaborators of a single document to speaking directly to a single, canonical server. This introduces resource constraints on that server and a single point of application failure.
Embracing Concurrency with CRDTs
How do CRDTs solve the central gatekeeper problem? They don’t need to solve it, they just entirely avoid it. There is no gatekeeper.
CRDTs are a category of data structures designed to support distributed systems. They mathematically guarantee eventual consistency, even across unreliable networks. CRDTs can be used offline by a single user in isolation, in a direct peer-to-peer communication network, or in a more traditional client-to-server communication network. These communications can come and go with the guarantee that when they’re eventually re-established, all parties will talk and come back to an eventually-consistent (read: identical) understanding of the common, final state.
CRDTs achieve this guarantee by implementing merge functions which follow three, simple mathematical rules. They must be:
- Commutative
- Associative
- Idempotent
Or in English: To be a valid CRDT, when merging a set of operations, the merge must always come to the same result regardless of the order in which the operations executed. The merge must be able to run on any combination of operations. And, if the set contains duplicate operations, those duplications mustn’t change the result. These shifts, duplications, and varying combinations cannot alter the final result of the resolved operations’ merge.
If these requirements are met, then all parties involved are mathematically guaranteed to have the exact same information, no matter the order in which they received and executed the changes. This feature is what allows participants to go offline for a period, even making their own changes while away, only to eventually come back, communicate, and automatically merge and agree on the same eventual result. No network connection or central server necessary.
For example, a Grow-Only Counter data type can be written to meet the CRDT criteria by implementing its merge using a MAX function. This counter can be shared and manipulated by any number of users and they will always agree on the final value because:
- It’s Commutative:
MAX(1, 2) == MAX(2, 1) == 2. - It’s Associative:
MAX(1, MAX(2, 2)) == MAX(MAX(1, 2), 2) == 2. - And it’s Idempotent: No matter how many times
MAX(1, MAX(1, MAX(1, 2)))is executed, it’s always2.
Interestingly, because CRDTs carry this auto-merge behavior as part of their data structure, existing applications can add collaboration with offline-support with relatively few changes. For example, the open source Pixel Art to CSS — a single-user pixel art generator — was extended by Ink & Switch to support multiple current users editing a single artboard, as well as branching artboards to suggest edits in PixelPusher.
Problems and Complexities with CRDTs
As with everything, CRDTs aren’t without their own problems and complexities.
CRDTs are eventually consistent. There may be a significant amount of time between now and eventually. So, in the meantime, this eventuality does require you to recognize, and possibly handle, those moments in between. The way in which you decide to handle those moments in between will vary per application and use case.
CRDTs require more storage space and computation than vanilla data structures. This is because all operations carry the operation, a unique identifier, and an identifier of the client requesting the operation. In small data sets, the metadata associated with these operations can dwarf the data. There are techniques to mitigate this overhead (including delta encoding, run-length encoding, compression), but their efficiency varies depending on the data structure and use case.
Finally, mathematically-correct results are not always human-expected results. When operations conflict and data is merged, it is done in a way that conforms to the commutative, associative, and idempotent rules. But, there are times when two operation sets have “equal” priority (two offline users changed the same word in a Google Doc, for example). In order to guarantee the eventually consistent requirement, this must be rectified using an application-specific algorithm to ensure all parties will resolve this equal priority condition in the same way (the operation from the highest client identifier wins, for example).
CRDTs in Production
As mentioned earlier, CRDTs are reaching the end of their research and development phase, but that doesn’t mean that they haven’t already been utilized in production applications. They bring a great many benefits to both new and existing applications. And, if you decide to take a risk on CRDTs, it’s important to know that you aren’t going it alone.
SoundCloud switched to CRDTs to manage social post broadcasting across all of their users to avoid quadratic storage growth requirements as their platform usage grows. Redis Enterprise uses CRDTs to allow Redis to be used in globally-distributed, highly-available, multi-master configurations. The Phoenix Framework uses CRDTs to power Phoenix Presence for keeping clusters in sync, allowing users to chat, and discovering application services. And Riot Games uses CRDTs to power the League of Legends in-game chat, allowing over 7 million concurrent players to share over 10,000 messages per second.

If you’re interested in learning more about CRDTs, check out crdt.tech for papers, implementations, and other resources. Or, to see some examples of CRDTs in JavaScript, see automerge on GitHub.
Ten Years of Brains: EdTech Lessons in the Decade After Rails for Zombies

10 years have passed since Rails for Zombies and though EdTech is constantly evolving, there are still lessons to learn. Find out more.